
Hola! hoy vamos a poner a prueba un MongoDB con mil millones (1.000.000.000) de puntos geoespaciales (latitud y longitud).
Este es uno de una serie de 3 motores de búsqueda que he querido poner a prueba (MongoDB, Solr y Elasticsearch) para ver si realmente son capaces de trabajar bien bajo una ingente cantidad de datos.
Estas pruebas son un poco peculiares ya que las hice creando coordenadas geoespaciales para dibujarlas en un mapa de un proyecto. Para los que les suene chino tengan en cuenta que no es mas que guardar una latitud y una longitud.
Bien, Lo primero que quiero presentares es el ordenador de pruebas:
Como ven es un ordenador de medias/altas prestaciones y aunque no es un servidor en toda regla lo vi mas que suficiente para estas pruebas.
La instalación de MongoDB la he dejado por defecto. No ajusté nada.
Bien la primera parte era la de carga de datos. Para esto hice la prueba cargando la misma cantidad de puntos via import de mongo (comando "mongoimport") y vía nodejs.
Finalmente me decanté por Nodejs dado que los tiempos de carga apenas diferían entre las dos herramientas con la ventaja de que Nodejs me permite ir logueando todo lo que me haga falta a medida que pasa por los bulk de carga.
Con bulk de carga me refiero a que en lugar de hacer un insert por cada uno de los "Point" (conjunto de coordenadas) los he insertado en paquetes de miles para no generar tanto cuello de botella en las operaciones de lectura/escritura.
NOTA: 1k = mil, 1m = 1 millón.
Hice pruebas de inserción de a 10k, 100k, 1m, 2m. No pude pasar de los 2m debido a la ram. De hecho a mas Points encolaba para insertar mas RAM me usaba (lógicamente) y por encima de los 2m me quedaba sin memoria y Node petaba.
Finalmente me decanté por la inserción de paquetes de 100k en 10k ciclos y 1m en 1k ciclos. Vamos allá:
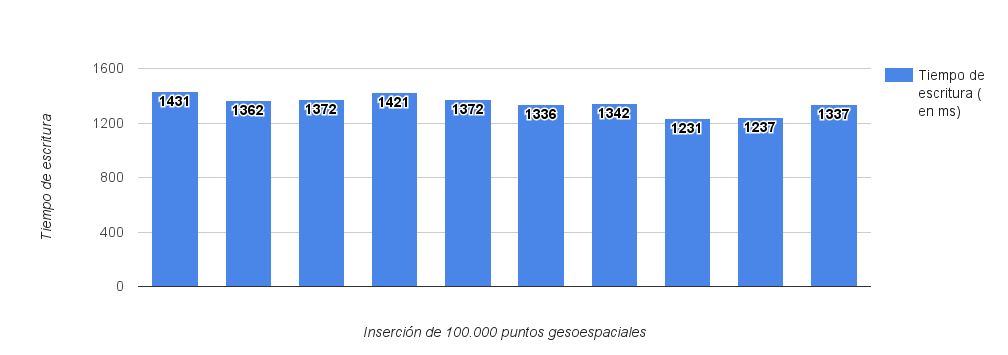
En la imagen cada medición corresponde a el tiempo que ha tardado Mongo en insertar 100k de Points. El tiempo medio que ha tardado en insertarlos ha sido de 1344ms.
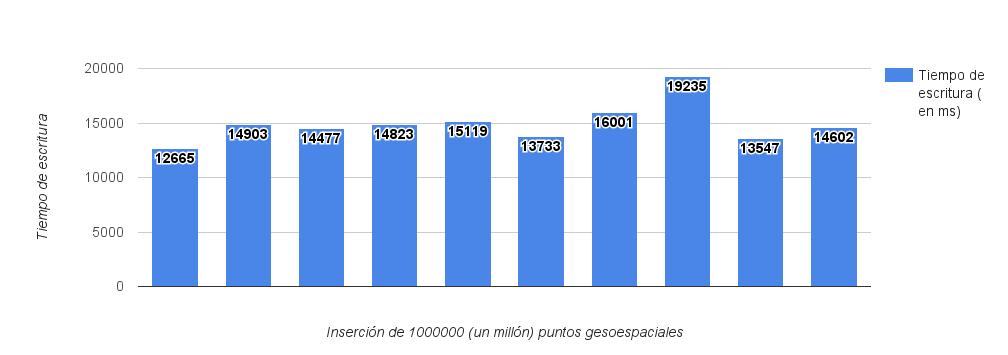
En este caso al insertar una cantidad 10 veces mayor que en el ejercicio anterior nos ha quedado una media final de 14910ms en completar la carga.
Por tanto. Si Mongo es capaz de insertar una media de 74399 puntos por segundo cuando le mandamos paquetes de 100k y 67066 puntos por segundo cuando le mandamos 1m, estamos ante una perdida de performance de un 44% al insertar bulk mas grandes.
Entonces, como la inserción de a 100k iba mas rápida fue la que seleccioné para cargar los 1000 millones. Esto teóricamente me ha tardado 224 minutos (3hs y 44m). Y digo teóricamente porque estoy extrapolando datos. No hice la prueba de medir el total cuando hice la inserción. Pero vamos que los números no mienten.
La DB entera teóricamente pesa 91.9GB pero en disco pesa "solo" 43.04GB gracias al motor WiredTiger de MongoDB que comprime los datos en disco.
También creo que es interesante mencionar que una vez creada la DB la indexé para poder hacer las búsquedas (olvídense de hacer una búsqueda sin indice) lo que me creó unos 25GB adicionales pero con compresión aplicada ocupa 11.7GB.
Lo que en total nos da unos 54,74GB de uso en disco con la DB y el indice.
Es el momento de hacer pruebas y ver que puede hacer Mongo con todos estos datos. Como ya mencioné las búsquedas son geoespaciales. Puntualmente son búsquedas radiales.
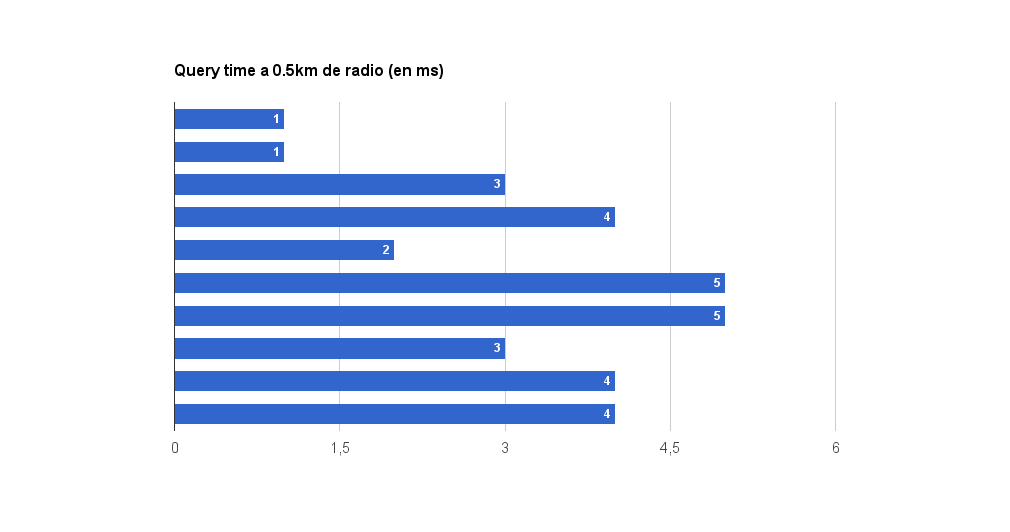
Sinceramente creí que estaban mal las mediciones cuando vi esto. Tarda 3ms en encontrar una media de 5.6 puntos en el mapa? NO ME LO CREO!. Pero si señor, repetí las pruebas y luego las pruebas con radios mayores confirman la consistencia de los resultados. Estoy asombrado.
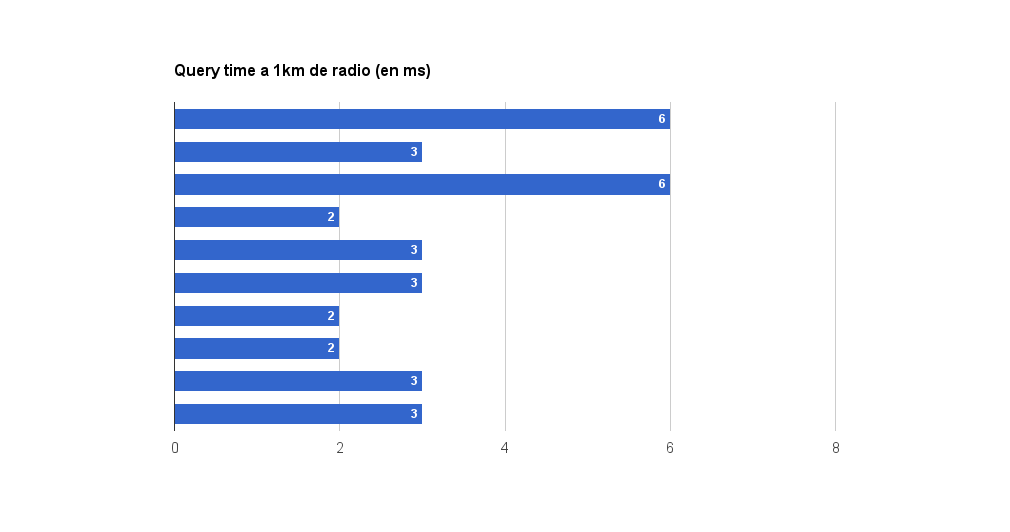
Curiosamente aquí encuentra casi la misma cantidad de puntos y la velocidad sigue siendo pasmosa.
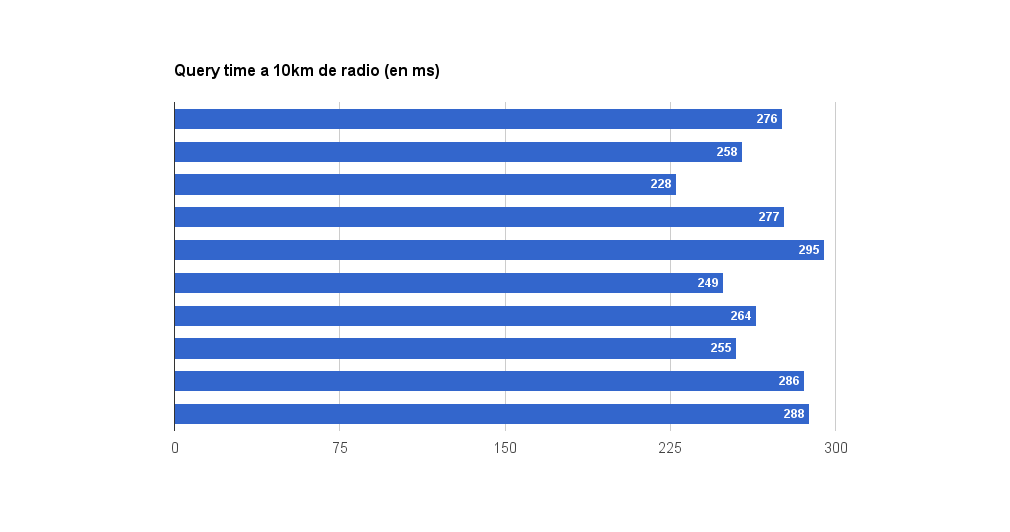
Aquí cambia un poco la cosa. Comenzamos a hacer búsquedas que devuelven muchos mas resultados y tiempos de respuesta mas allá de los 5ms. En búsquedas de 10km encontramos una media de 730 puntos con un tiempo medio de búsqueda de 268ms.
A partir de este radio incluyo la cantidad de RAM que consume dicha búsqueda para que nos hagamos una idea. En este caso las búsquedas a 10km almacenan en RAM 100mb por cada búsqueda.
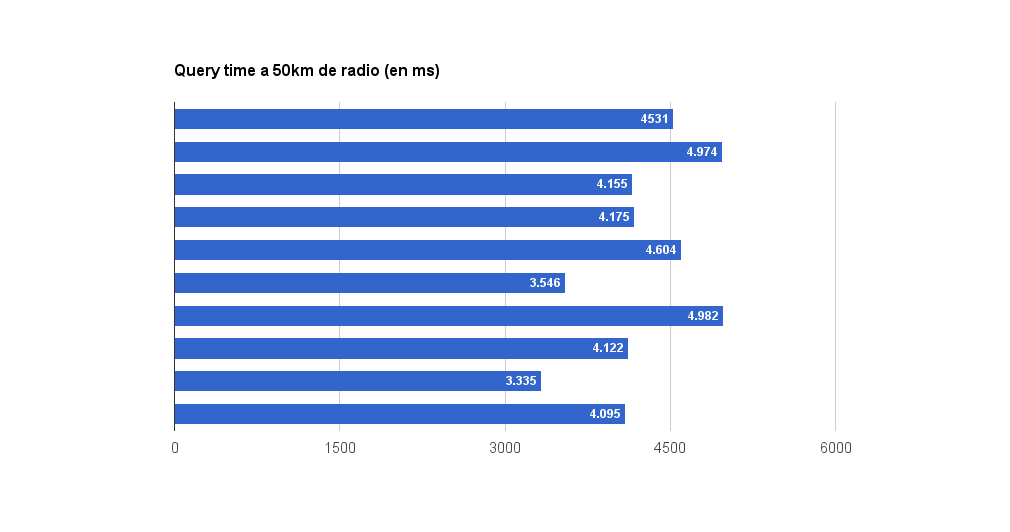
En búsquedas de 50km los resultados el tiempo y el consumo de RAM se ponen mas interesantes. 15022 puntos en 4250ms con un consumo de 800mb por consulta.
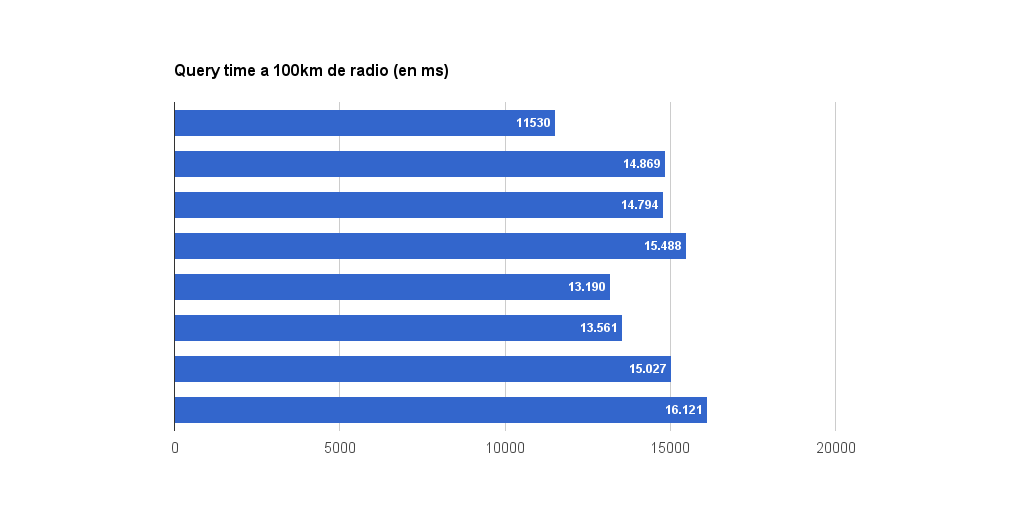
Ultimo test. En este caso hemos hallado una media de 63317 puntos en 14323ms y un consumo de RAM de 3.6GB por consulta.
Las búsquedas parciales son una búsqueda realizada en sobre de una búsqueda anterior y por lo tanto ya cacheada.
En este ejercicio hice una búsqueda a 10km y 50km de radio y posteriormente hice una búsqueda que abarcará la mitad de la primer búsqueda y la otra mitad de una zona que anteriormente no había sido consultada.
¿Para que hice esto? Para confirmar que los resultados de las búsquedas que se iban realizando se iban cacheando en RAM para ser accedidas mas velozmente.
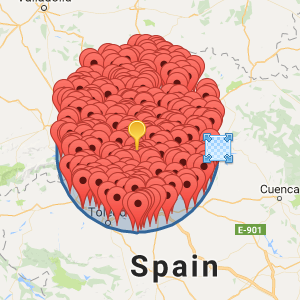
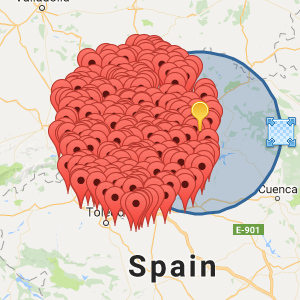
Como resultados he conseguido lo siguiente:
Para búsqueda en un radio de 10km:
Para búsqueda en un radio de 50km:
Como pueden ver se confirma fácilmente que los puntos buscados mientras no se reinicie MongoDB se almacenan en RAM.
Bueno, espero que les sea de utilidad todo esto. Pronto hablaré de Solr con los mismos tests a ver que tal le va.
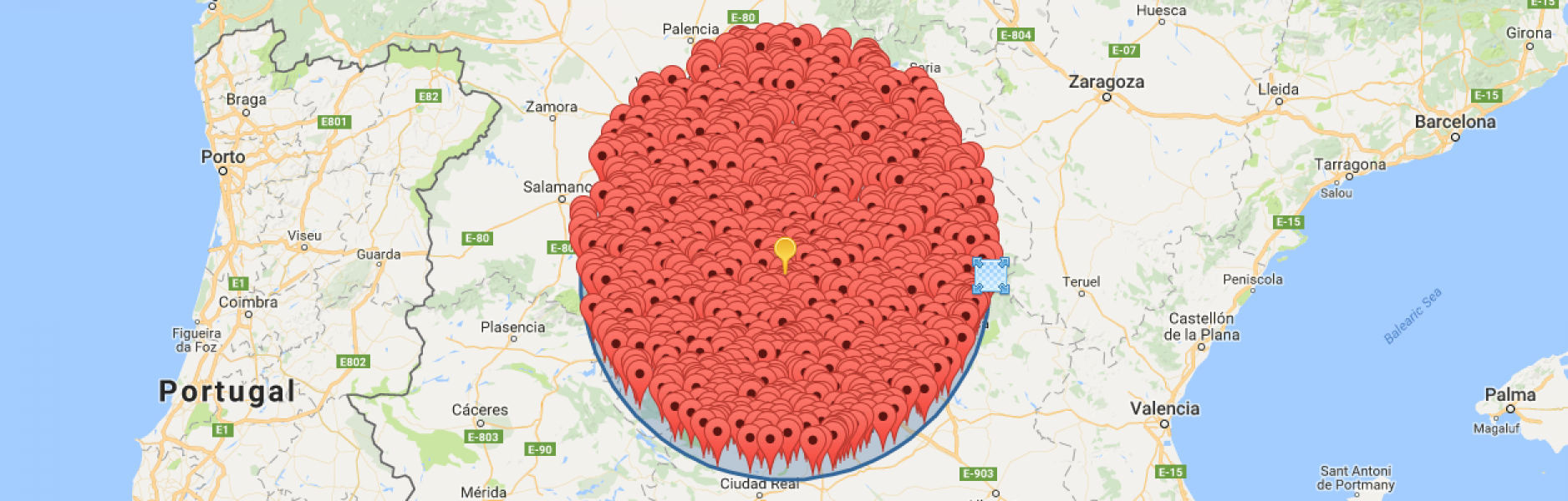
Perlita! ¿Capy como se ve una búsqueda de 2000km dibujado en un mapa?. Así!:
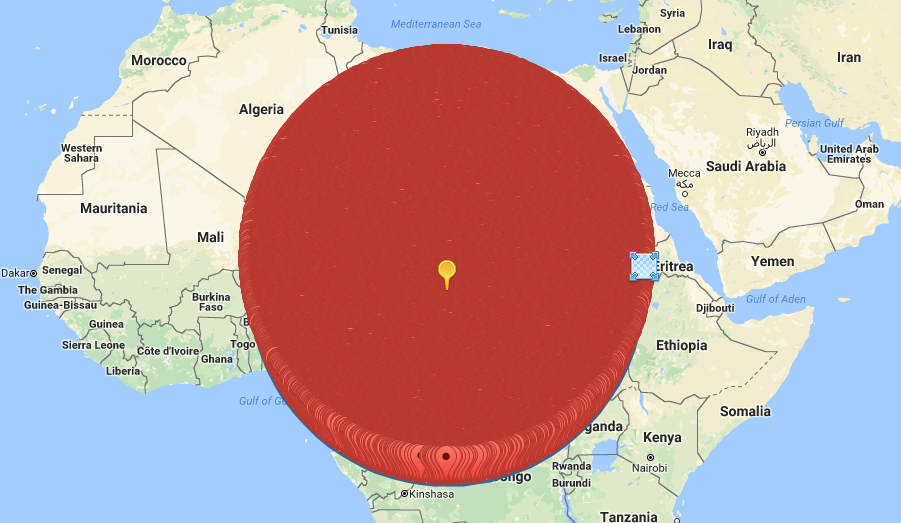
Saludos!
Colaborador oficial
del programa:

Recursos para pymes
y autónomos
frente
al COVID-19


Agregar nuevo comentario